
Welcome, readers! As exciting and intriguing as the field of Machine Learning is, it often greets us with a handful of concepts that seem to tangle us into a web of confusion, if not understood properly. So today, we’ve decided to untangle two such crucial concepts – Bias and Variance, and understand their interplay in Machine Learning.
At the heart of our discussion lies the ‘Bias-Variance Tradeoff’, a complex concept that leaves many scratching their heads. The objective of this blog is to make these topics as simple as pie! We will decipher what Bias and Variance are, explore their effects and consequences on Machine Learning models, and understand why balancing these essentials matters. Not just that, we also plunge into techniques for handling them and observe their real-life applications.
So, let’s buckle up and prepare to embark on this intriguing journey of mastering the complex arena of the Bias vs Variance Tradeoff in Machine Learning. Stay tuned!
Fundamentals of Machine Learning
Welcome to the exciting world of Machine Learning (ML)! At its core, ML is just a clever way of creating algorithms that can learn from and make predictions or decisions based on data. Let’s break it down.
First, let’s answer the big question: What is Machine Learning, exactly? Consider it as teaching computers to learn from experience. The “learning” part occurs when the computer can improve its performance from exposure to relevant data.
The types of Machine Learning algorithms are diverse, so here’s a manageable bite-size rundown: * Supervised Learning — This is just where we explicitly train the algorithm, using labeled data. It’s like a teacher supervising the learning process. * Unsupervised Learning — Here, the machine learns on its own, finding patterns and insights from unlabelled data. * Reinforcement Learning — This approach allows the machine to interact with its environment by producing actions and learning from the results.
Stay tuned as we dive into the concepts of bias and variance in Machine Learning in our next section.
Understanding Bias in Machine Learning
Let’s imagine ourselves as a striving archer who consistently hits the left side of the target. The inability to hit the bullseye is referred to as bias in Machine Learning.
So, what exactly is Bias? In machine learning, it exemplifies the error from erroneous assumptions in the learning algorithm. When a model has a high bias, we say that the model is oversimplified, overlooking the complex realities of the data.
Now, consider how bias influences our Machine Learning model. If our model continually misses the mark and does not learn or adapt its aim, it will never hit the bullseye. Similarly, a high bias machine learning model oversimplifies the real-world, leading to poor accuracy in predictions, and hence underfitting the data.
In a nutshell, the consequence of high bias is underfitting. The model’s representation of the data becomes too naïve, inevitably leading to misinterpretations and inaccurate results. Balancing the level of bias is critical to develop models that can accurately interpret the complexities of the real world.
Understanding Variance In Machine Learning
Deep diving into the world of machine learning, let’s take a look at Variance now. In simplest terms, variance refers to the extent our machine learning model’s predictions shift based on fluctuations in our training set.
Put simply, a model with high variance tends to overfit the training data; way too eager to impress! This overfitting leads the model to adapt to minor irregularities or noise in the data which – let’s just say – doesn’t work well when it sees new, unseen data.
Impact of High Variance
So, what might happen if our model exhibits high variance? Imagine if each time you tried a new trendy restaurant, you decided on the spot that this was your all-time favourite and turned your back on your previous favourites – seems a bit hyperbolic, right? Well, this is akin to what models with high variance do. Just like your dining preferences, models that overfit training data fail to generalize well to unseen datasets. Hence, they exhibit poor predictive performance on fresh data.
Bottom line, getting that balance between bias and variance is key in the arena of machine learning. On to that next!
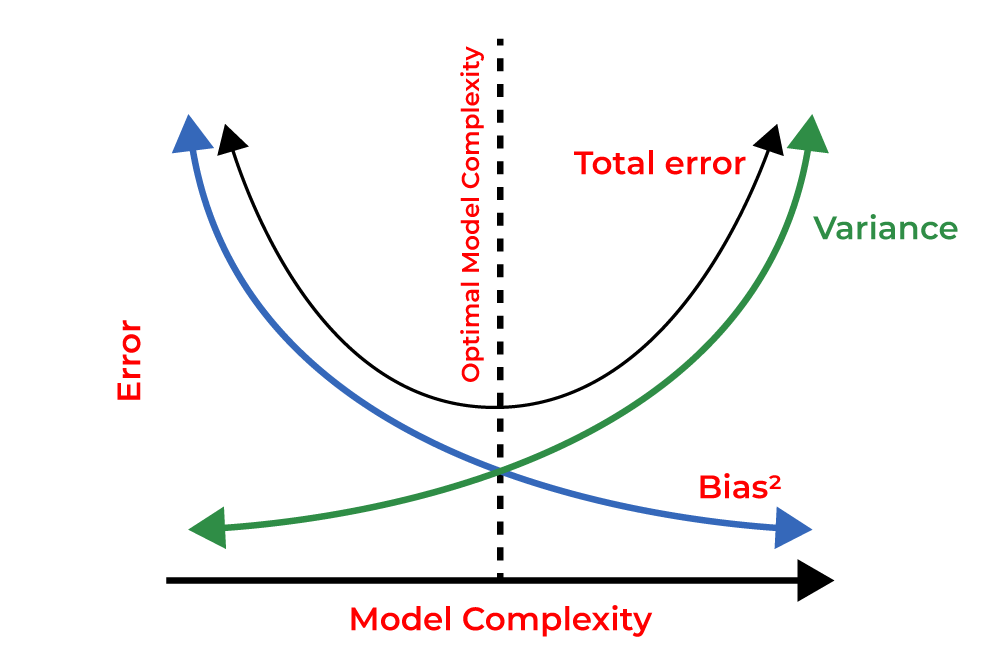
Understanding the Bias-Variance Tradeoff
In the universe of Machine Learning (ML), the Bias-Variance Tradeoff refers to a crucial balancing act that happens during model training. It essentially decides the tradeoff between a model’s ability to fit well to training data (low bias), and its ability to produce consistent predictions across different datasets (low variance).
The importance of balancing bias and variance cannot be overemphasized as an optimal ML model finds the right equilibrium between the two. You may think of it like tuning a guitar string – too loose (high bias), and the sound is deep and dull; too tight (high variance), and the note is high and erratic.
To paint a clearer picture, let’s consider a dart game. A player with a high bias consistently misses the bullseye, thus his darts cluster far from the target (underfitting). Conversely, a high-variance player’s darts scatter wide, indicating inconsistency (overfitting). The aim is to be a player whose darts frequently land on or near the bullseye – a healthy balance of bias and variance.
Techniques to Handle Bias and Variance
Dealing with bias and variance is an integral part of creating an effective Machine Learning model. It requires a firm understanding of the underlying principles and the ability to apply practical methods. Here are some of the key techniques.
Using Validation Techniques
Validation Techniques are essential in preventing overfitting thereby controlling variance. Cross-validation is a common method where the dataset is split into a training and test set.
Regularization
Regularization, such as L1 (LASSO) or L2 (Ridge), can be used to prevent overfitting and tackle high variance. They work by adding a penalty term to the magnitude of the coefficients.
Feature Selection
Proper Feature Selection removes irrelevant features thereby reducing both bias and variance. It can be done through various methods like backward elimination, forward selection, and recursive feature elimination.
Ensemble Methods
Finally, Ensemble methods such as Random Forest and Bagging can effectively balance bias and variance by combining the decisions from multiple models.
Using these techniques judiciously would pave the way for a more accurate and reliable Machine Learning model.
Real-Life Applications of Bias and Variance in Machine Learning
Understanding bias and variance is not just a theoretical concept. Let’s delve into practical scenarios where we might prefer models with high bias or low variance.
Scenarios where high bias is advantageous
High bias models, also known as underfit models, can be useful when we need a general solution rather than a specific one. For instance, predicting the general trend of the stock market, weather pattern, or customer behavior. Here, overfitting can lead to inaccurate predictions due to noise or fluctuations in the market, thereby making high-bias models a safer choice.
Scenarios where low variance is advantageous
Low variance, on the other hand, is preferred when we need to capture every little detail. For tasks like image recognition, speech recognition, and medical diagnosis, which require pinpoint precision, models with low variance (overfit) can capture the intricate details necessary to generate accurate results.
Understanding the context and picking the right models is crucial to success in machine learning.
Conclusion
In our journey through machine learning, understanding the concepts of bias and variance forms the crux of successful model development. To recap, bias is the simplifying assumptions that a model makes to make the target function easier to approximate while variance is the amount a model’s predictions would change if different data were used for training.
It’s important to visualize bias and variance as two ends of a balancing scale. When one is high, the other is expected to be low, and vice versa. This give and take relationship is the foundation of the bias-variance tradeoff.
Understanding these terms well is not just about theory; it is very much integral to realizing accurate and reliable predictive models. Too much bias can lead to underfitting and missing relevant relations between features and target output, while high variance can lead to overfitting – modeling noise or random fluctuations in the training data that aren’t representative of the true underlying relationship.
Mastering the bias-variance tradeoff can thus put you a big step ahead in your data science journey.